Get Started & Usage#
To use the Hyperion API, start by setting up the client with an access token. Then, directly pass your query parameters and call the appropriate method to fetch the data.
The examples below show how to configure the client, apply filters to refine your request, and handle the results efficiently.
⮞ Set up the client by passing the access token to the HyperionApiClient class
from synmax.hyperion.v4 import HyperionApiClient
access_token = 'your access token goes here'
client = HyperionApiClient(access_token=access_token)
⮞ Examples of using the client object to fetch datasets.
Tip
Narrow down your request to receive a more manageable result set when using the .df() method. The .df() method returns a pandas DataFrame containing the data.
When fetching large datasets, consider using .__next__() to retrieve data in chunks and persist them to disk.
⮞ Option 1: Fetch all of the result and return it as a Pandas DataFrame.
import datetime
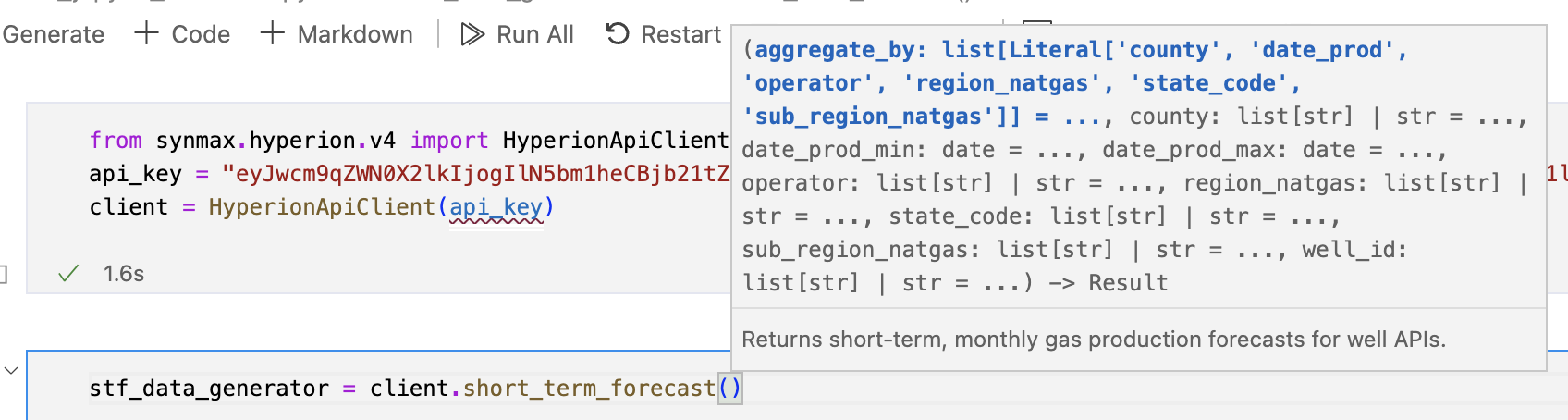
stf_data_generator = client.short_term_forecast(
aggregate_by=["date_prod", "sub_region_natgas"],
date_prod_min=datetime.date(2025, 5, 1),
date_prod_max=datetime.date(2025, 6, 30),
)
stf_dataframe = stf_data_generator.df()
⮞ Option 2: Fetch the data in chunks using __next__() implicitly and write to a file.
import json
import datetime
stf_data_generator = client.short_term_forecast(
aggregate_by=["date_prod", "sub_region_natgas"],
date_prod_min=datetime.date(2025, 5, 1),
date_prod_max=datetime.date(2025, 6, 30),
)
output_file = "haynesville_stf.json"
with open(output_file, "w") as f:
f.write("[\n")
first = True
for data in stf_data_generator:
if not first:
f.write(",\n")
json.dump(data, f, indent=2, default=str)
first = False
f.write("\n]")
⮞ Use Autocomplete feature
The synmax-api-python-client SDK provides autocomplete functionality when used in code editors or IDEs that support Python type hints.
See available methods to fetch datasets:
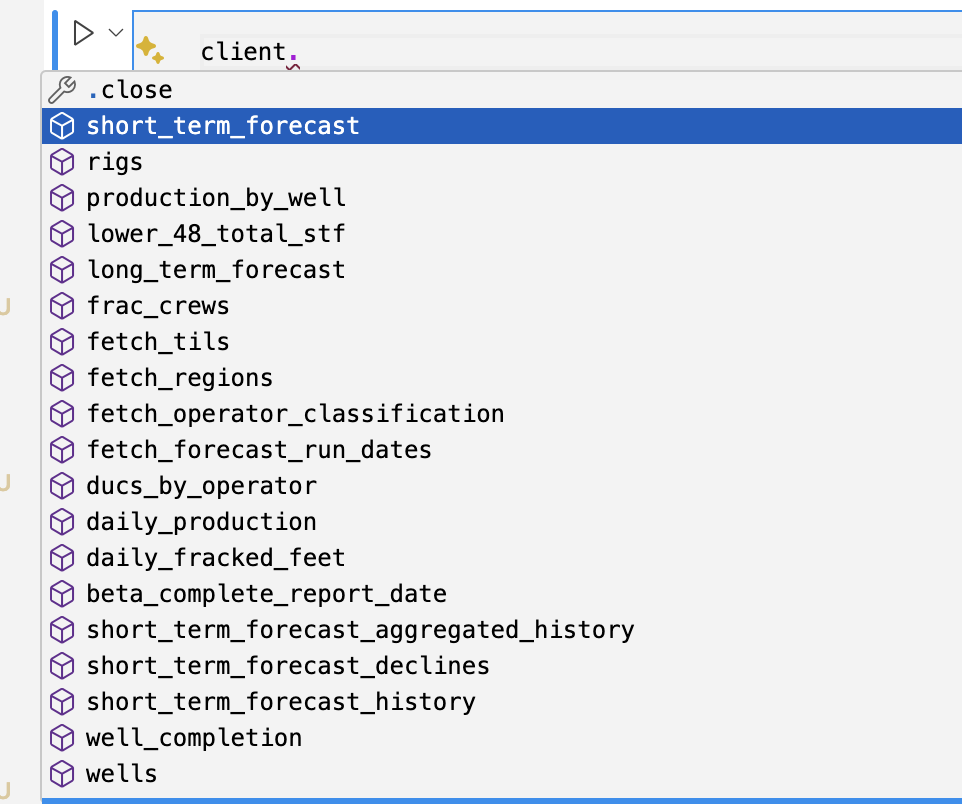
After selecting a method, view its parameters: